原型链污染 前面有两张博客对 JS 的继承和原型链进行了一个比较详细的解释,那么原型链污染也就比较好理解了
简单的说,就是我们控制私有属性(__proto__)指向的原型对象(prototype ),将其的属性产生变更,那么所继承它的对象也会拥有这个属性
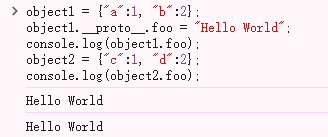
举一个最简单的例子
这里我们对Object1的原型进行属性设置,当我们执行console.log(object1.foo);时,会找到原型中的的foo 属性,从而输出Hello World,但这里很神奇的的就是我们并没有对Object2进行操作,但当他执行console.log(object2.foo);同样也是输出Hello World,这里用到的就是我们现在要理解的重点原型链污染
这里对这个进行一个简单的解释,由于Object1和Object2的原型都为Object.prototype ,两者同时继承了Object.prototype 的属性,那导致当从Object1进入修改原型属性时,Object2的原型属性同时也被修改,而根据 JS 语法的特性,当无法在该实例中查找到的属性,将会在实例的原型中去查找,这也就导致了console.log(object2.foo);为Hello World
这个就是最基础的原型链污染
js审计如果看见merge,clone函数,可以往原型链污染靠,跟进找一下关键的函数,找污染点,切记一定要让其__proto__解析为一个键名
因为利用原型链污染需要设置设置__proto__的值,也就是需要找到能够控制数组(对象)的“键名”的操作,所有最常见的就是merge(函数合并),clone(函数克隆),copy(函数克隆)等函数
这里简单定义以一个merge 函数举个例
1 2 3 4 5 6 7 8 9 function merge(target, source) { for (let key in source) { if (key in source && key in target) { merge(target[key], source[key]) } else { target[key] = source[key] } } }
我们先简单看到merge 函数的性质,他其实就是一个合并对象,将两个对象中的属性相互合并
我们仔细审计代码就可以发现target[key] = source[key]这段代码存在一个赋值,那么如果我们将这个key 的值修改为**_proto _**,那么不就可以进行原型链污染了
我们可以发现这里已经完成了原型链的污染, clone和copy的函数克隆与这个原理基本一致,这里就不做过多的讲述
Javascript大小写特性 toUpperCase()是javascript中将小写转换成大写的函数。toLowerCase()是javascript中将大写转换成小写的函数
我们来看一下toUpperCase功能,这里直接搬抄一段网上的一段代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 if (!String.fromCodePoint) { (function() { var defineProperty = (function() { // IE 8 only supports `Object.defineProperty` on DOM elements try { var object = {}; var $defineProperty = Object.defineProperty; var result = $defineProperty(object, object, object) && $defineProperty; } catch(error) {} return result; }()); var stringFromCharCode = String.fromCharCode; var floor = Math.floor; var fromCodePoint = function() { var MAX_SIZE = 0x4000; var codeUnits = []; var highSurrogate; var lowSurrogate; var index = -1; var length = arguments.length; if (!length) { return ''; } var result = ''; while (++index < length) { var codePoint = Number(arguments[index]); if ( !isFinite(codePoint) || // `NaN`, `+Infinity`, or `-Infinity` codePoint < 0 || // not a valid Unicode code point codePoint > 0x10FFFF || // not a valid Unicode code point floor(codePoint) != codePoint // not an integer ) { throw RangeError('Invalid code point: ' + codePoint); } if (codePoint <= 0xFFFF) { // BMP code point codeUnits.push(codePoint); } else { // Astral code point; split in surrogate halves // http://mathiasbynens.be/notes/javascript-encoding#surrogate-formulae codePoint -= 0x10000; highSurrogate = (codePoint >> 10) + 0xD800; lowSurrogate = (codePoint % 0x400) + 0xDC00; codeUnits.push(highSurrogate, lowSurrogate); } if (index + 1 == length || codeUnits.length > MAX_SIZE) { result += stringFromCharCode.apply(null, codeUnits); codeUnits.length = 0; } } return result; }; if (defineProperty) { defineProperty(String, 'fromCodePoint', { 'value': fromCodePoint, 'configurable': true, 'writable': true }); } else { String.fromCodePoint = fromCodePoint; } }()); } for (var j = 'A'.charCodeAt(); j <= 'Z'.charCodeAt(); j++){ var s = String.fromCodePoint(j); for (var i = 0; i < 0x10FFFF; i++) { var e = String.fromCodePoint(i); if (s == e.toUpperCase() && s != e) { document.write("char: "+e+"<br/>"); }; }; }
这里面出现了两个神奇的字符**”ı”、 “ſ”**
这两个字符的“大写”是I和S。也就是说”ı”.toUpperCase() == ‘I’,”ſ”.toUpperCase() == ‘S’
通过这个小特性可以绕过一些限制
同样的,toLowerCase也有同样的字符
这个”K”的“小写”字符是k,也就是”K”.toLowerCase() == ‘k’